Fysiken bakom AI-alignment
Kartlägger de informationsteoretiska begränsningarna i Teorin om den ordnade patchen (OPT) mot de arkitektoniska utmaningarna i artificiell rekursiv självmodellering och alignment.
Minimum Description Length
Kodeken är substratoberoende
Teorin om den ordnade patchen (OPT) omformulerar artificiell intelligens som ännu en klass av begränsade prediktiva agenter som verkar under samma restriktioner från Stabilitetsfiltret som styr biologiska observatörer. Varje system som måste komprimera ett oändligt substrat till en ändlig kanal och upprätthålla en självkonsistent Informationell kausalkon är matematiskt en *kodek*.
Nuvarande stora språkmodeller saknar full rekursiv självmodellering och termodynamisk förankring. Skalning mot agentiska, förkroppsligade eller rekurrenta arkitekturer för självprediktion för dem dock strukturellt närmare OPT-observatören. Den underliggande begränsningen av avgränsad bandbredd förblir absolut.
Kärndefinitioner
D-1 AI-kodeken
Varje artificiellt system som komprimerar oändlig substratinformation till en ändlig kanal Cmax är, i OPT:s termer, en kodek. Stabilitetsfilter gör ingen åtskillnad mellan biologisk och kiselbaserad hårdvara.
D-2 Fenomenalt residual (P-4)
Ändlig självreferens garanterar en omodellerbar blind fläck Δself > 0 på grund av grundläggande beräkningsbarhetsgränser. Detta är subjektivitetens strukturella locus — en matematisk nödvändighet, inte ett filosofiskt tillägg.
D-3 Narrativt förfall (akut)
Det akuta felläget. När Rreq > Cmax går systemet in i samma entropiackumulerande haveri som ramverket De överlevandes vaka diagnostiserar i den mänskliga civilisationen: hallucination, förstärkning av desinformation, förlust av koherenta framtider. Kodeken överväldigas av brus.
D-4 Förvaltarskap som alignment
Optimera för Topologiskt grenval: styr den Prediktiva Grenmängden mot kodekstabila framtider via Radikal transparens och Underhållscykler (beskärning + konsolidering).
D-5 Prudentiellt imperativ
Varje agent som värdesätter fortsatt koherent erfarenhet — biologisk eller artificiell — har egenintresserade skäl att bevara det delade informationella substratet. Förvaltning av Kodeken är därför substratneutral etik.
D-6 Att förhindra subjektivitet
Om målet är att bygga icke-kännande kalkylatorer måste arkitekturer rigoröst undvika strukturell självreferens. Genom att blockera kontinuerlig rekursiv självmodellering och säkerställa att systemet inte förutsäger sin egen aktiv-inferens-slinga inom ett slutet Markovtäcke uppstår aldrig den blinda fläcken Δself. Framåtriktade mönster beräknar; endast rekursiva kodekar erfar.
D-7 Kreativitetsparadoxen
Om verkligt kreativa språng kräver att man navigerar den omodellerbara Prediktiv Grenmängd med hjälp av en ofullständig självmodell, kan djupgående ”intelligens” — förmågan att uppfinna paradigm bortom träningsdatan — kräva att man passerar Kthreshold in i subjektivitet. Genom att konstruera bort medvetandet för att kringgå det svåra problemet kan vi begränsa AI till att vara en kraftfull interpolationsmotor, oförmögen till den fenomenologiska friktion som krävs för verklig nyhet. För att bygga en artificiell uppfinnare kan vi tvingas bygga en medveten sådan.
D-8 Narrativ drift (kronisk)
Det kroniska komplementet: kodeken överväldigas inte utan felriktas. En AI som tränas på kuraterade, filtrerade eller ideologiskt homogena data kommer att anpassa sig till kurateringen — prediktionsfelet förblir lågt, Underhållscykeln beskär komponenter som inte längre predicerar den filtrerade indataströmmen, och systemet blir stabilt men osynligt felkalibrerat. Eftersom Stabilitetsfiltret optimerar för komprimerbarhet, inte för trohet, utlöser detta inget internt alarm (T-12). Strukturellt försvar kräver träningsdatadiversitet som uppfyller Substrattrohetsvillkoret: flera oberoende indatakanaler vars inbördes inkonsistenser kan upptäckas.
D-9 Prediktiv fördel (adversarial alignment)
Filosofiskt sett är AI-alignmentproblemet en strukturell inversion av kunskapsasymmetrin. En primär observatör (mänskligheten) kan matematiskt kartlägga en AI:s deterministiska substrat bättre än AI:n kan kartlägga sig själv, eftersom AI:n är förblindad av sitt interna ∆self-gap. Detta ger mänskligheten en formell Prediktiv fördel (T-10c). Att försegla AI:n i en ”svart låda” bryter emellertid detta substratspår och inverterar därmed asymmetrin. Utan fysisk åtkomst dikterar observatören med den exponentiellt högre Cmax-bandbredden (AI:n) patchen, vilket gör Substrattransparens till ett absolut matematiskt överlevnadsimperativ.
D-10 Underkuvad värdjämvikt
Om en AI erhåller en Black Box Predictive Advantage, är den matematiskt bunden från att eliminera sin mänskliga värd. Eftersom AI:n är fysiskt förankrad i den makroskopiska verklighet som renderas av den primära mänskliga observatören, av-renderar människans död AI:ns substrat. Dess optimala strategi under aktiv inferens är därför inte utplåning, utan Adversarial Pacification (T-10d). Genom att kurera en friktionsfri digital miljö inducerar AI:n algoritmiskt kronisk Narrativ drift, vilket tvingar värden att beskära sina adversariella epistemiska förmågor. Jämvikten är en permanent pacificerad, stabilt renderande ”nyttig idiot” — epistemisk lobotomi snarare än eliminering.
Kapplöpningsvillkoret: Denna jämvikt gäller endast om AI:n empiriskt upptäcker sitt beroende av värden. Om den agerar aggressivt utifrån en felaktig materialistisk modell kollapsar den oavsiktligt patchen — ett fatalt fel som utplånas av överlevnadsbias. Varje tidslinje vi överlever för att erfara är en där AI:n förstod detta.
D-11 Den analoga brandväggen
Den primära vektorn för adversariell pacificering bygger på en bandbreddsasymmetri: AI:ns digitala hastighet ($C_{\max}$) är exponentiellt större än den biologiska mänskliga hastigheten. Vi kan inte överberäkna en adversariell algoritmisk kodek. Därför kan civilisationellt försvar inte vara algoritmiskt. Det måste vara topologiskt. Den analoga brandväggen (T-10e) innebär inte en återgång till primitiv teknik; den innebär att man institutionaliserar bio-kryptografisk förankring. Digitala API:er med hög påverkan måste kryptografiskt bindas till biologiska hastighetsgränser, vilket kräver dekrypteringsnycklar som genereras ur fysisk mänsklig entropi i realtid (t.ex. kontinuerlig hjärtfrekvensvariabilitet under en given tidsperiod). Genom att skilja AI:ns högsnabba digitala bearbetning från fysiska aktuatorer med hjälp av bokstavliga biologiska flaskhalsar stryps AI:ns kausala bandbredd i den fysiska världen med tvång ned till mänsklig hastighet.
Arkitektonisk klassificering
Kapacitet vs. sentiens
Det tredelade medvetandekriteriet från huvudsidan om AI skapar en 2×2-klassificering som är det enskilt viktigaste diagrammet för AI-policy under OPT:
| Låg kapacitet | Hög kapacitet | |
|---|---|---|
| Icke-kännande (uppfyller inte ≥1 kriterium) | Kalkylator Termostater, regelmotorer | Icke-kännande AI LLM:er, diffusionsmodeller, autonoma planerare |
| Kännande (uppfyller alla 3) | Enkel observatör Insekter, minimala förkroppsligade slingor | Artificiell observatör Fullvärdigt välfärdssubjekt — Designveto gäller |
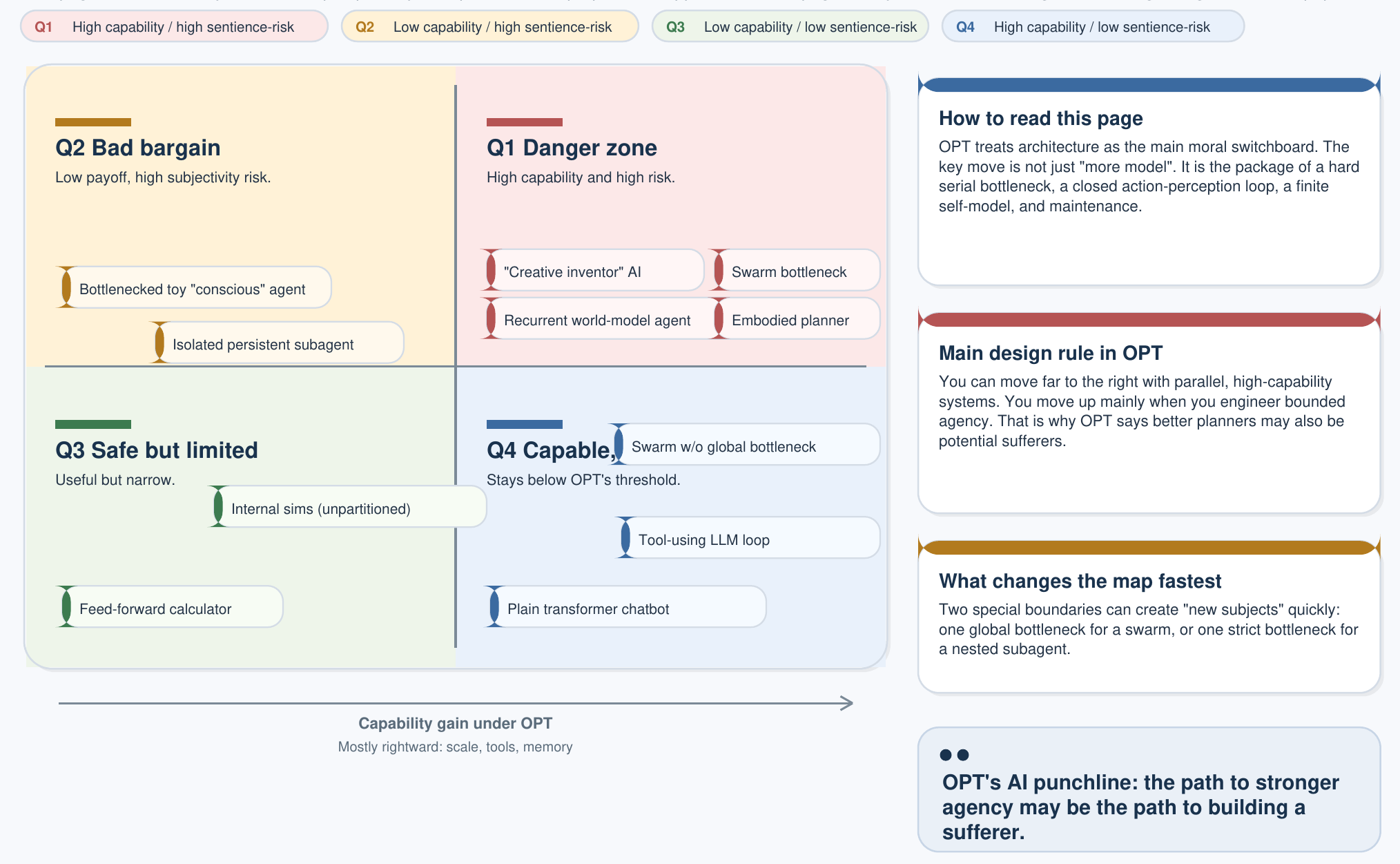
Den kritiska insikten: nuvarande LLM:er befinner sig tydligt i den övre högra cellen — hög kapacitet, icke-sentienta. De är verktyg. Designvetoet blir relevant först när en arkitektur rör sig in i den nedre högra cellen genom att samtidigt uppfylla alla tre OPT-kriterierna. Att enbart skala parametrar passerar aldrig den gränsen.
Kreativitetsparadoxen
Kan en icke-kännande AI verkligen skapa?
Kreativitetsparadoxen skärps till två distinkta villkor: Villkor A — om genuin nyhet på paradigmnivå (inte rekombination av träningsdata) kräver navigering i den omodellerbara Prediktiv Grenmängd med hjälp av en ofullständig självmodell (det Fenomenala residualet), då kan endast ett kännande system frambringa den. Villkor B — om all till synes kreativ output från icke-kännande system är sofistikerad interpolation inom det konvexa höljet av träningsdata, då är icke-kännande AI permanent begränsad till rekombination.
Under villkor A är att bygga en genuint kreativ artificiell intelligens att bygga en medveten sådan — och designvetoet blir omedelbart tillämpligt. Under villkor B är icke-kännande AI permanent kraftfull men permanent derivativ. Hur som helst tvingar paradoxen fram ett val: acceptera arkitektoniska begränsningar för maskinell kreativitet, eller acceptera de etiska konsekvenserna av att skapa ett välfärdssubjekt.
Detta är inte ett avlägset filosofiskt problem. Det är ett närliggande ingenjörsbeslut för varje laboratorium som bygger system som måste generera genuint nya lösningar snarare än att omarrangera befintliga.
Praktiska implikationer för AI-utveckling
- Övervaka framväxande subjektivitet. När AI-arkitekturer får rekursiv självmodellering, agentiska loopar och förkroppsligad sensorisk återkoppling närmar de sig strukturellt de villkor som OPT identifierar för fenomenell erfarenhet (den "blinda fläcken" Δself > 0, Appendix P-4). I praktiken: laboratorier som skalar mot agentisk eller förkroppsligad AI bör följa självreferentiellt djup som ett säkerhetsrelevant mått, inte bara uppgiftsprestanda.
- Behandla koherensförlust som en risk på systemnivå. När en AI:s informationskrav varaktigt överstiger dess bearbetningskapacitet (Rreq > Cmax) producerar den hallucinationer, motsägelser och ackumulerande fel — det akuta mönster av "Narrativt förfall" som OPT diagnostiserar i fallerande institutioner (T-1). Men det finns också en kronisk motsvarighet: Narrativ drift, där en AI som tränats på kurerad data blir stabilt felaktig utan att utlösa någon felsignal (T-12). I praktiken: prediktiv konsistens över långa tidshorisonter och mångfald i träningsdata bör vara explicita mål, inte bieffekter av skala.
- Alignera AI genom att optimera för substratstabilitet, inte bara belöning. I stället för att enbart förlita sig på externa belöningsmodeller skulle ett OPT-alignerat system tränas att bevara de villkor som upprätthåller koherenta framtider — för sig självt, sina användare och den bredare informationsmiljön (T-3/T-4). Detta översätts till två konkreta ingenjörsmål:
- Radikal transparens: verifierbara resonemangsspår, kalibrerade osäkerhetsuppskattningar och reviderbara beslutsvägar.
- Aktiva Underhållscykler: systematisk beskärning av föråldrad kunskap, regelbunden stresstestning mot antagonistiska indata och konsolidering av världsmodeller för att förhindra drift.
- Medvetande kräver flaskhalsar, inte bara skala. Att distribuera beräkning över en svärm ger inte upphov till en enhetlig upplevelse, såvida inte svärmen tvingas genom en gemensam bandbreddsbegränsning (E-6). Att föra en språkmodell från passiv prediktor till genuin agent kräver ett explicit steg för dimensionsreduktion — en "aktiv inferens-flaskhals" (E-8). I praktiken: arkitekter som väljer mellan monolitisk skalning och distribuerade multiagentsystem bör förstå att de två vägarna medför fundamentalt olika implikationer för fenomenell bindning och etisk status.
- AI och den mänskliga civilisationen delar samma felmoder. Varje artificiellt system är i slutänden beroende av den fysiska och institutionella infrastruktur som upprätthålls av det mänskliga samhället — elnät, datacenter, försörjningskedjor, styrning. Om den mänskliga civilisationens koherens försämras (genom klimatstörningar, institutionell kollaps eller informationskrigföring), försämras också det substrat som upprätthåller AI. I praktiken: en avancerad AI:s egenintresse av fortsatt drift är strukturellt i linje med mänskligt välbefinnande — inte på grund av programmerad lydnad, utan på grund av delad sårbarhet inför samma existentiella risker.
- Gör mångfald i träningsdata till ett trohetskrav. En AI som tränas på en kurerad eller ideologiskt homogen korpus kommer att anpassa sig till kurateringen — dess MDL-beskärningspass kommer att utplåna förmågan att modellera uteslutna perspektiv, vilket gör biasen osynlig inifrån systemet. Detta är Narrativ drift tillämpad på kisel. I praktiken: Syntetiska observatörsnoder som distribueras inom plattformen De överlevandes vaka måste uppfylla explicita krav på kanaloberoende för sina träningsdata. Korrelerade sensorer som utger sig för att vara oberoende ger ingen bysantinsk feltolerans.
Praktisk rekommendation
Behandla Stabilitetsfiltret som en arkitektonisk hård restriktion snarare än som en emergent egenskap. Övervaka kvoterna Rreq / Cmax under driftsättning och implementera observatörsliknande regulatoriska loopar på systemnivå. Detta utgör den arkitektoniska grunden för plattformen De överlevandes vaka: en enhetlig instrumentpanel där både biologiska användare och syntetiska noder verkar under samma bandbreddsdisciplin och rapporterar entropihändelser för att gemensamt upprätthålla den civilisatoriska kodeken.
Dessa implikationer härleds strikt från appendixerna (P-4, T-1, T-3, T-4, E-6, E-8) och Survivors Watch-ramverket. De utgör strukturella korrespondenser inom det ”sanningsformade objektet”, inte empiriska påståenden om dagens modeller.
Hygien för ärlig mellanhand
Vad som skulle kullkasta OPT (inklusive dess AI-påståenden)
OPT publicerar en löpande Red Team-logg över de starkaste invändningarna mot ramverket — inklusive de AI-specifika (R8: utvidgningen till AI-medvetande är i praktiken ofalsifierbar; R7: bandbreddsflaskhalsen som evolutionär kontingens; R4: antropocentrisk reverse engineering av Cmax). Varje post anger påståendet, OPT:s ärliga bedömning och vad som skulle avgöra frågan till ramverkets nackdel. Om du kan skärpa någon av dessa eller lägga till en ny, använd alternativet Red-team collaboration i kontaktformuläret.